
Transformers, but if you examined the idea from atop a 100,000 foot cliff.
Transformers, but if you examined the idea from atop a 100,000 foot cliff.
For Ananth: try to keep up! :)

Disclaimer: This is an extremely high-level explanation of Transformers. I’m merely going to explain what they are and how they work.
What are Transformers?
It’s a type of neural network architecture. Neural networks are effective models for analyzing complicated data types like images, videos, audio, and text.
But, different types of neural nets are optimized for different types of data.
For images, you’d use a Convolutional Neural Network (CNN)— designed to vaguely mimic how our human brain processes vision.
Since 2012, we’ve had neural nets that have been good at identifying and classifying images, but we did not have much luck analyzing language (whether for translation, text summarization, or generation).
Before transformers, we used Deep Learning to understand text with a Recurrent Neural Network (RNN). An RNN would process each word one at a time and sequentially respond wrt its function.
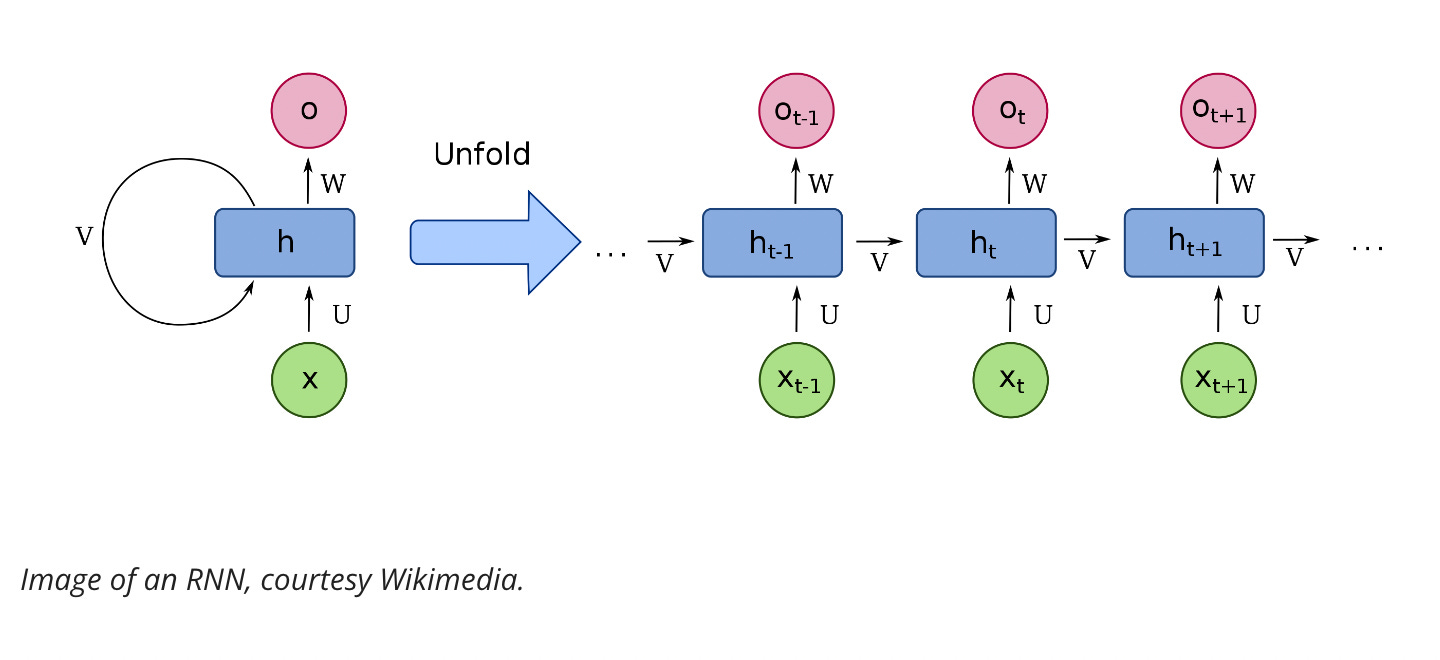
RNNS cons:
First, they struggled to handle large sequences of text, like long paragraphs or essays. By the time reached the end of a paragraph, they’d forget what happened at the beginning. An RNN-based translation model, for example, might have trouble remembering the gender of the subject of a long paragraph.
Secondly, RNNs were hard to train. They were notoriously susceptible to the vanishing/exploding gradient problem. Even more problematic, RNNs were hard to parallelize because they processed words sequentially. This meant you couldn’t just speed up training by throwing more GPUs at them, which meant, in turn, you couldn’t train them on all that much data.
How do Transformers Work?
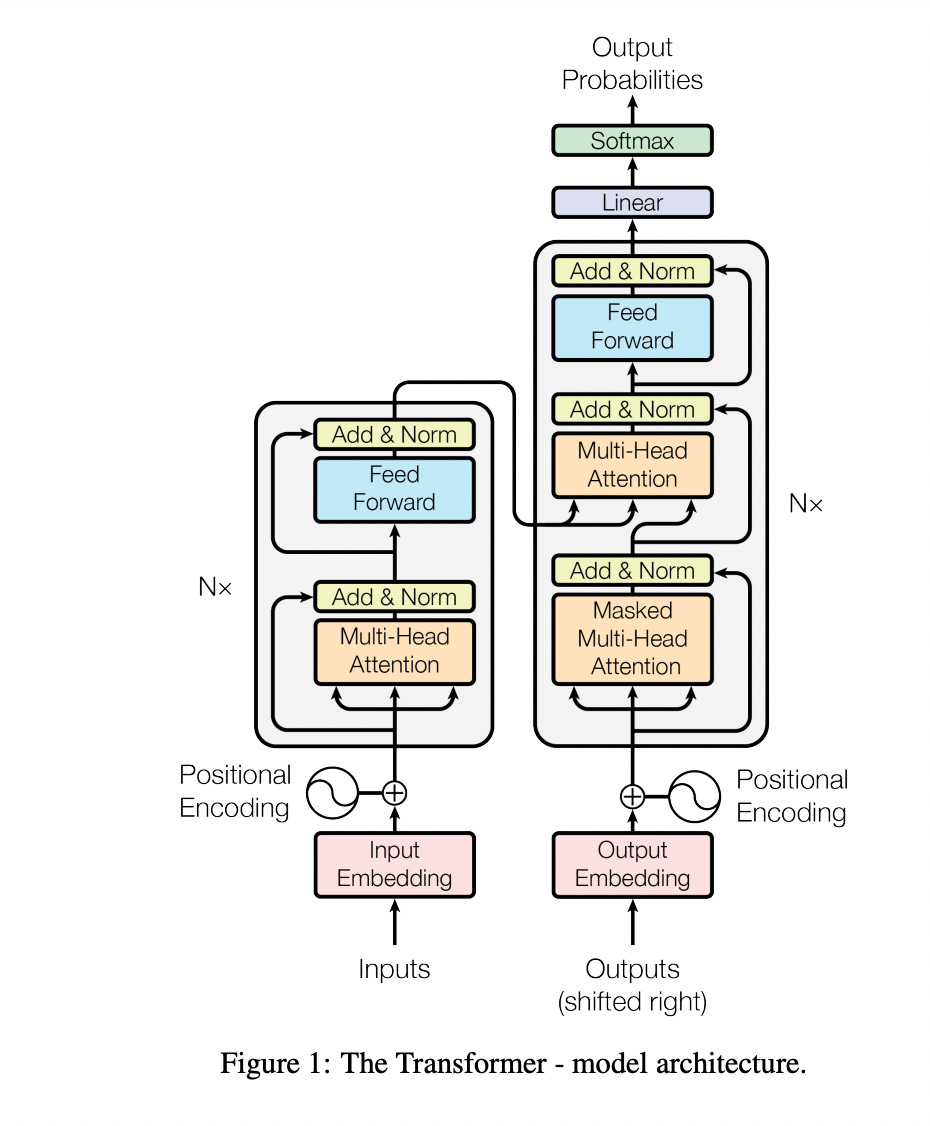
This Transformer diagram is from the “Attention Is All You Need Paper.”
The main thing to note:
Positional Encoding, Attention, and Self-Attention are the main innovations of transformers that make them effective.
Positional encodings
Let’s say we’re trying to translate text from English to French. Positional encodings are the idea that instead of looking at words sequentially, you take each word in your sentence, and before you feed it into the neural network, you label it with a number depending on what order the word is in the sentence.
At first, before the Transformer has been trained on any data, it doesn’t know how to interpret these positional encodings. But as the model sees more and more examples of sentences and their encodings, it learns how to use them effectively.
I’ve done a bit of over-simplification here–the original authors used sine functions to come up with positional encodings, not the simple integers 1, 2, 3, 4–but the point is the same. Store word order as data, not structure, and your neural network becomes easier to train.
Attention
Let’s say we’re translating a difficult sentence from English to French: “The agreement on the European Economic Area was signed in August 1992.” Translating that sequentially will not prove to be an accurate translation, of course. In French, some words are flipped, have a gendered agreement, and don’t translate exactly as you would in English. An Attention model will survey every text in the sequence before performing its function and creating the output. How does the model know which words to pay attention to?
It’s something learned over time from data — similarly to how humans prioritize attention based on what we have learned through our experiences. Only, for AI, its priors are the data it has collected. By seeing thousands of examples, the model learns about things as “intuitively” as a human does.
Self-Attention
A twist on traditional attention that helps you understand the underlying meaning in language to build a network that can do myriad language tasks. As transformers analyze tons of text data, they automatically build up an internal representation or intuitive understanding of language (eg. a model might categorize a software engineer, developer, and programmer the same as it learns that it’s used in similar contexts). The better the internal representation of a neural network (what I claim is a narrow version of human intuition), the more effectively the neural network learns and the better it will be at any language task.
The big positive of the Self-Attention is that it becomes more effective at understanding language if it is turned on the input text itself. For example, “Server, can I have a check?” and “Looks like I just crashed the server.” have different meanings of the term “server” because of the surrounding context. Self-Attention is meta in that it allows a neural network to understand a word in the context of the words around it. A Self-Attention model would be able to disambiguate what server means in each context based on “check” and “crashed” in each sentence. Self-attention helps neural networks disambiguate words, do part-of-speech tagging, entity resolution, learn semantic roles, and much more.
This is definitely a very high-level breakdown of Transformers, but I wanted to put this out there before I explore the “three-roots-deep” technicality like Jay Alammar does.